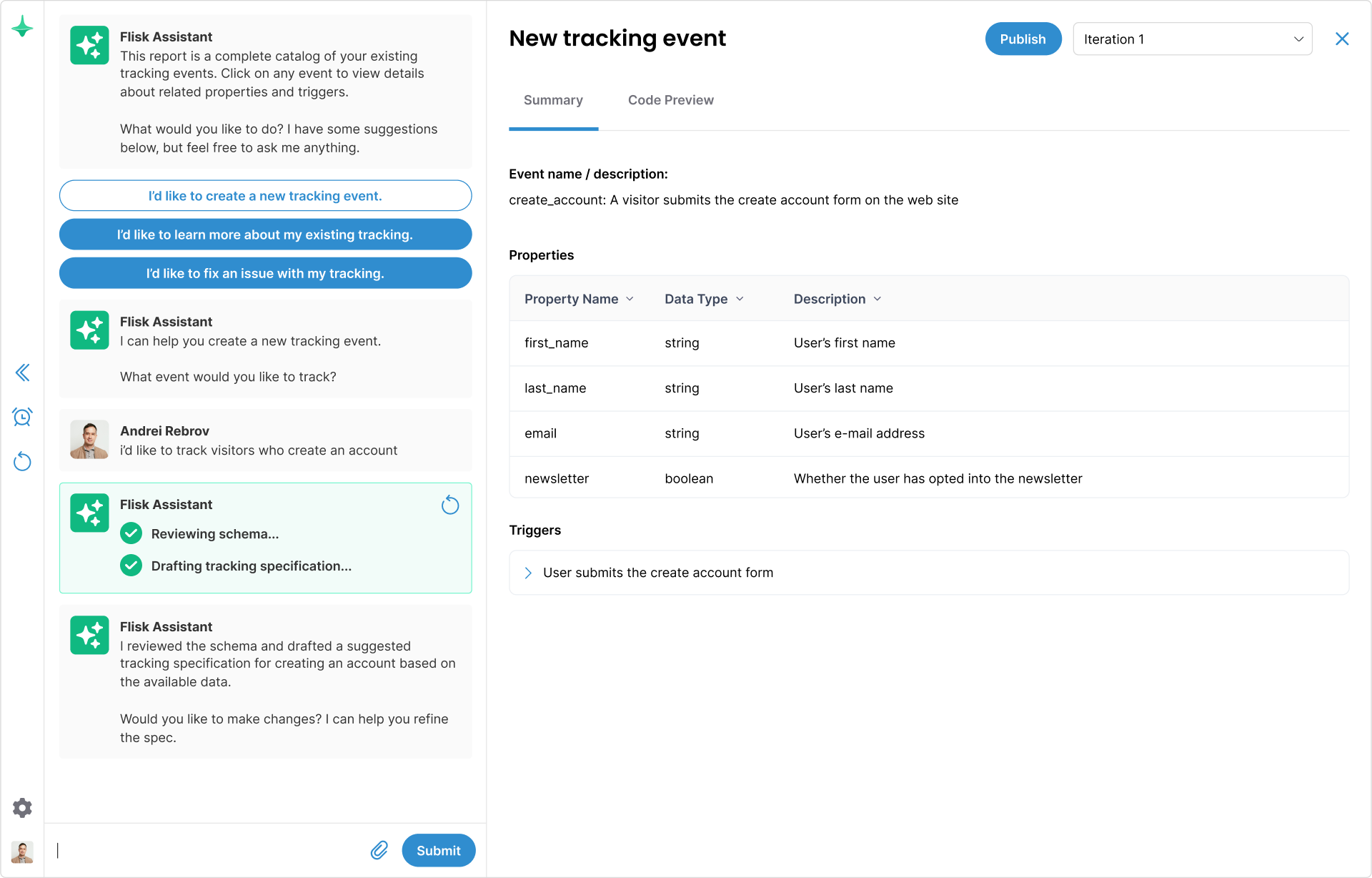
Your always-current event documentation
Flisk compiles a unified catalog of events, properties, and triggers directly from your code.
As your code changes, the documentation updates automatically — no manual upkeep required.
Automated documentation
Static analysis builds an authoritative event catalog
Continuous monitoring
Detects drift and broken implementations
Actionable alerts & recommendations
Clear reports that prioritize what needs fixing
Purpose-built for analytics engineers who need trustworthy documentation at all times.
Automated data schemas, without manual effort
“I need an up-to-date event catalog.”
Flisk's AI agents crawl your repos and auto-generate accurate documentation from the code you already have — no manual spreadsheets or cleanup required — saving days or even weeks.
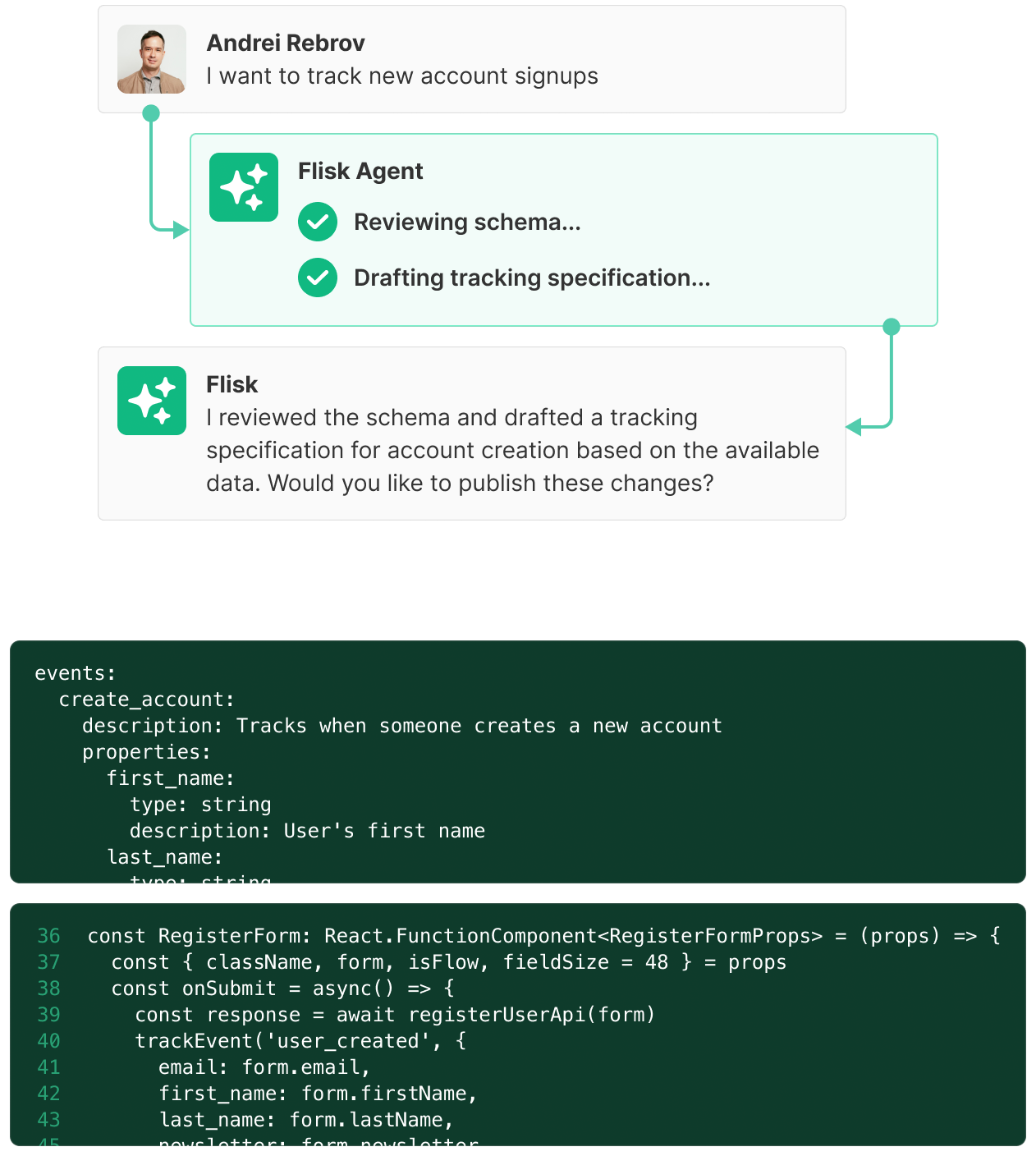

“But our system has years of tech debt.”
Flisk maps what exists today, cuts through years of tech debt by flagging inconsistencies and gaps, and keeps everything current automatically as code changes.
Proactively detect and fix documentation risks
Code changes that cause instrumentation drift are silent killers for analytics teams.
Flisk continuously monitors your codebases for missing events, name changes, and property type drift — and provides clear, actionable recommendations.

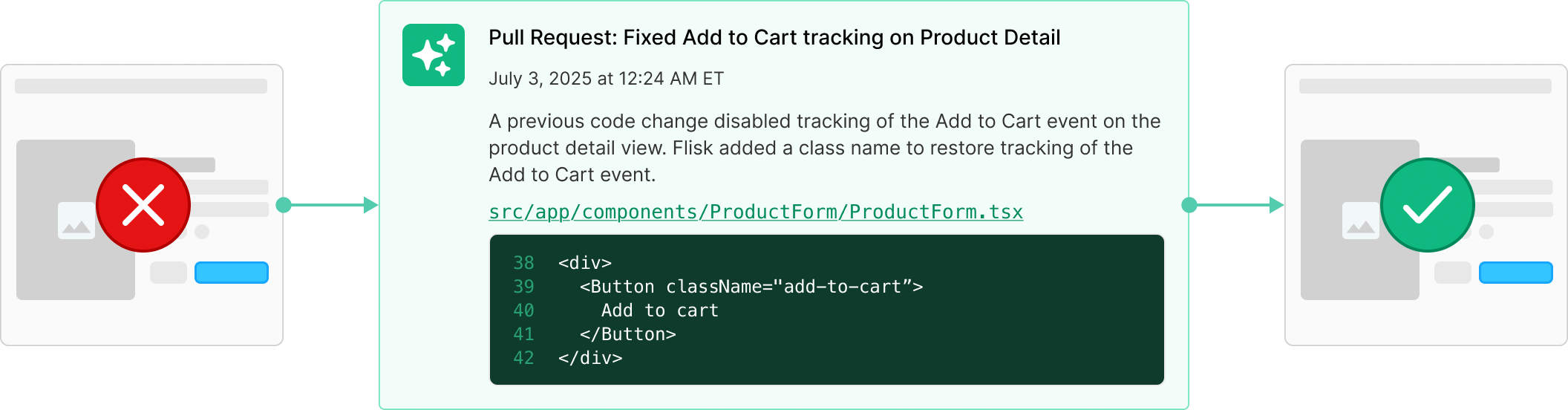
By the time you get the alert, Flisk has already gathered the context you need to resolve it.
Maintain an up-to-date event catalog automatically
AI-powered static analysis compiles a complete catalog of events, properties, and triggers, across services and platforms.
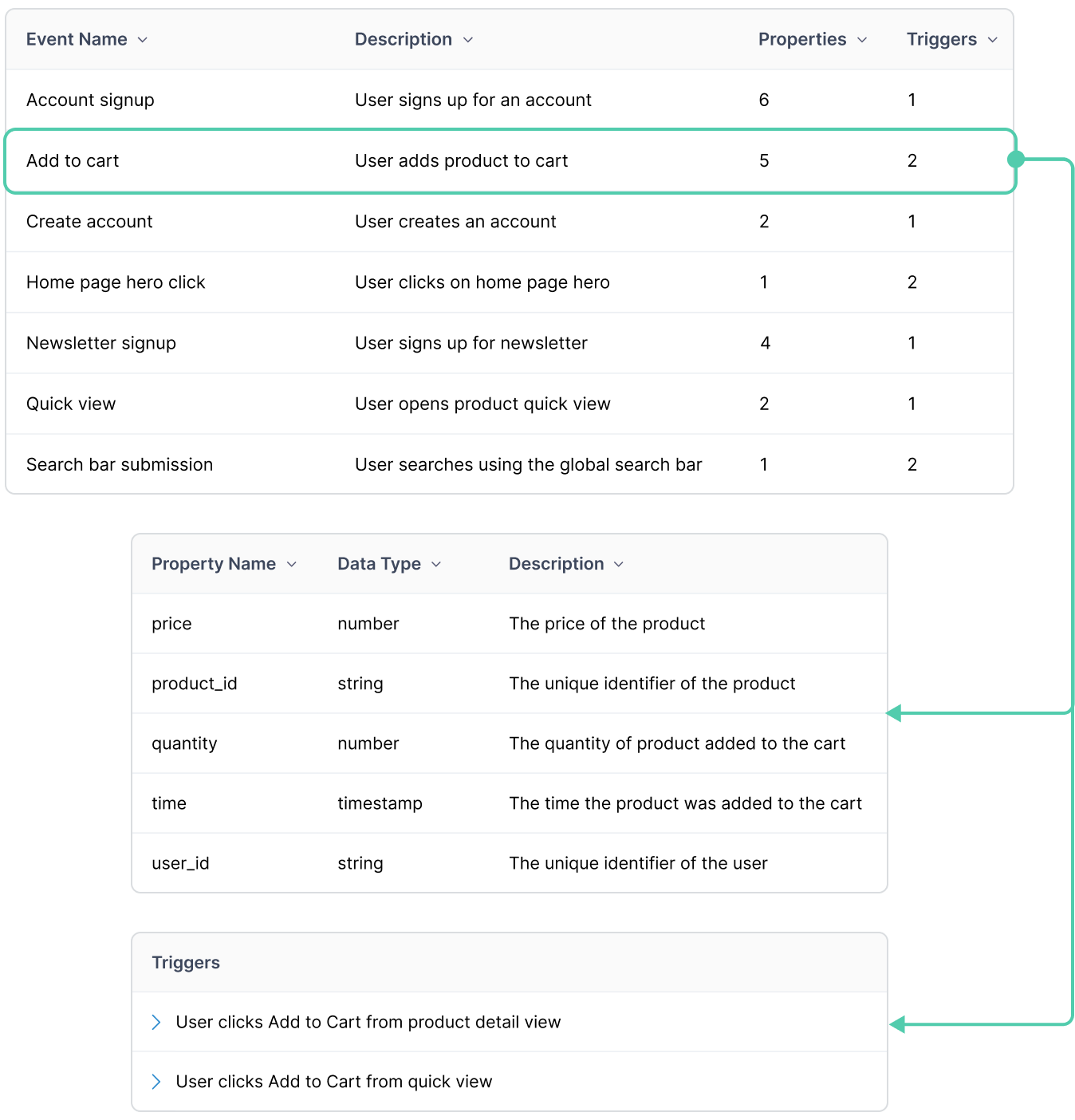

Use it as your source of truth for governance, QA, product analytics, and more.
Understand data from the source
Documentation starts at the source. Flisk analyzes the code that emits events to produce authoritative, in-context definitions — not after-the-fact tables stripped of meaning.

Starting from source code captures true intent, parameters, and triggers — aligning PMs, analysts, and engineers around a shared, always-current plan.
Improve governance with AI-aware conventions
Naming, casing, and typing inconsistencies create downstream data quality issues.
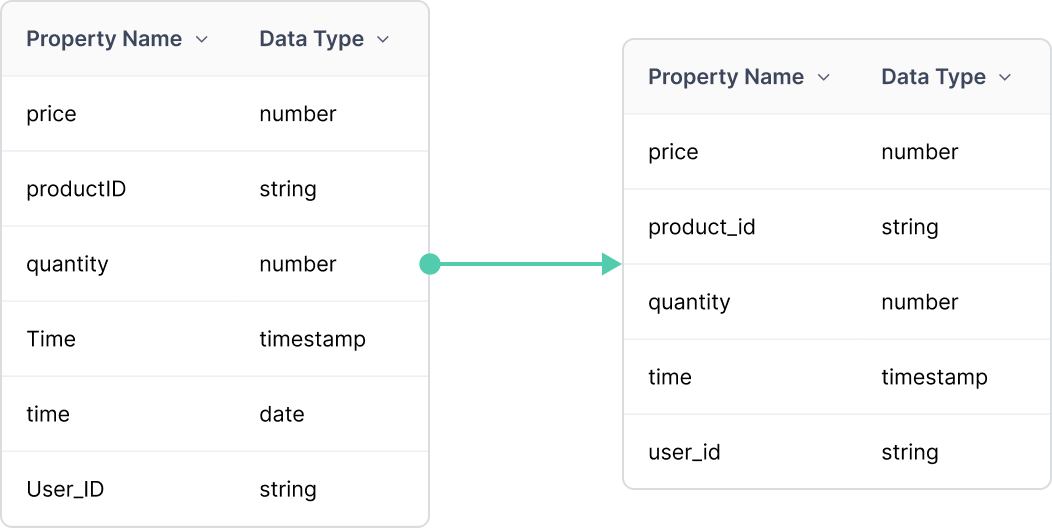
Flisk learns your conventions and highlights deviations, consolidating duplicates and preventing future drift.
Data that just works
Get reliable, current documentation without the manual work.
Say goodbye to endless tickets and inaccurate dashboards. Say hello to data that just works.
Frequently asked questions
How does Flisk create documentation from our code?
Flisk uses AI-powered static analysis to scan your repos and extract events, properties, and triggers. It compiles these into a centralized catalog that stays synchronized with your code.
We support all major tracking platforms: Google Analytics, Google Tag Manager, Segment, Mixpanel, Amplitude, mParticle, PostHog, Pendo, Heap, Snowplow, and Datadog. We also support any custom wrappers or event-producing code.
What does monitoring look for?
Flisk monitors for changes that impact data quality: renamed or removed events, property type drift, missing/unused events, and broken references.
Does this replace our existing analytics tools?
Flisk focuses on documentation and monitoring. It complements your existing data storage and collection tools by keeping your data definitions consistent and reliable.